# Population,总体
# 总体均值设置为100
mu <- 100
# 总体标准差设置为15
sigma <- 15
# 随机种子值设置为2026
set.seed(2026)
# 将ID与IQ存入数据表中
population10000 <- data.frame(
# 生成10000个ID(被试编号)
ID = seq(1:10000),
# 生成10000个均值为mu、标注差为delta的IQ分数
IQ = round(rnorm(10000, mean = mu, sd = sigma), 0)
)
# 查看数据表
# View(population10000)
# 查看数据表前6行
range(population10000$IQ)
## [1] 45 158
head(population10000)
## ID IQ
## 1 1 108
## 2 2 84
## 3 3 102
## 4 4 99
## 5 5 90
## 6 6 62
# 总体的实际均值
mean(population10000$IQ)
## [1] 100.0531
# 总体的实际标准差
sqrt(sum((population10000$IQ - mean(population10000$IQ))^2)/10000)
## [1] 15.01792总体分布,样本分布,抽样分布
Polulation, sample, and sampling distributions
1 总体
我们捏造一个人数为10000人的总体,为10000名被试设定编号ID,并捏造出其IQ数据,设定IQ的均值为100,标准差为15。
2 总体分布
总体分布(population distribution)是总体(10000名被试IQ得分)的分布。注意该分布的横纵坐标的全距。
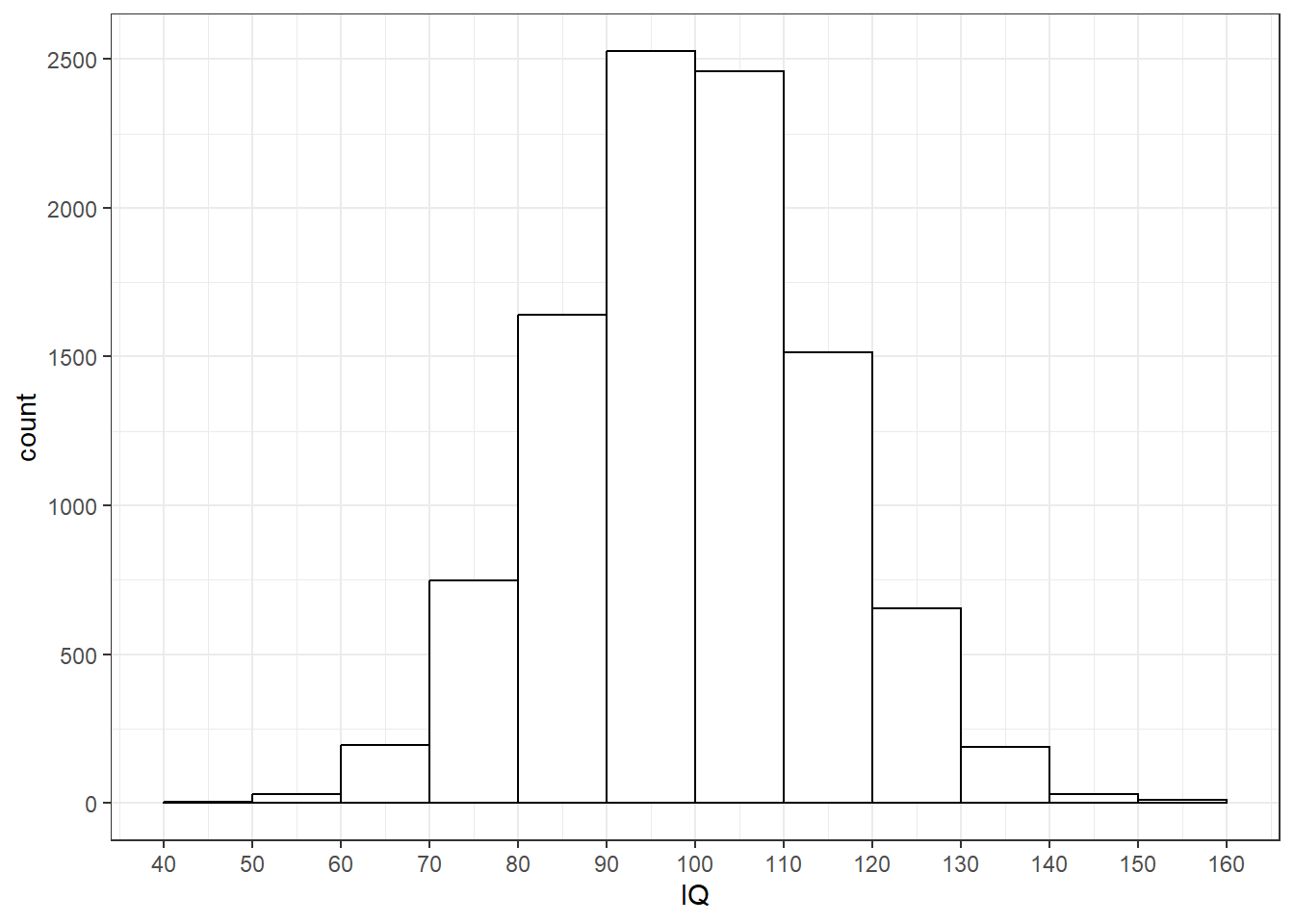
3 取样过程
接下来,我们模拟取样的过程。我们从N = 10000的总体中随机抽取一个样本量n = 100的样本。我们称这个样本为sample1。
4 样本
查看sample1中的数据。注意:被试ID的顺序是乱的,这是由随机取样导致的。
5 基于样本估计总体均值与标准差
样本的均值是总体均值的无偏估计。样本的标准差总是小于总体的标准差,因此使用样本的无偏标准差作为总体标准差的无偏估计。尽管名为“无偏”,实际上还是有偏差的。
# 取值范围
range(sample1$IQ)
## [1] 65 154
# 计算sample1的IQ的均值
sample1_mean <- mean(sample1$IQ)
sample1_mean
## [1] 99.2
# 计算sample1的IQ的标准差
sample1_sd <- sqrt(sum((sample1$IQ - sample1_mean)^2)/100)
sample1_sd
## [1] 15.12614
# sample1的无偏标准差(基于sample1估计总体的标准差)
sample1_sd_unbiased <- sqrt(sum((sample1$IQ - sample1_mean)^2)/(100 - 1))
sample1_sd_unbiased
## [1] 15.20234
# 使用`sd()`函数计算sample1的无偏标准差(总体标准差的估计值)
sd(sample1$IQ)
## [1] 15.202346 样本分布
样本分布(sample distribution)是样本中100个被试IQ得分的分布。
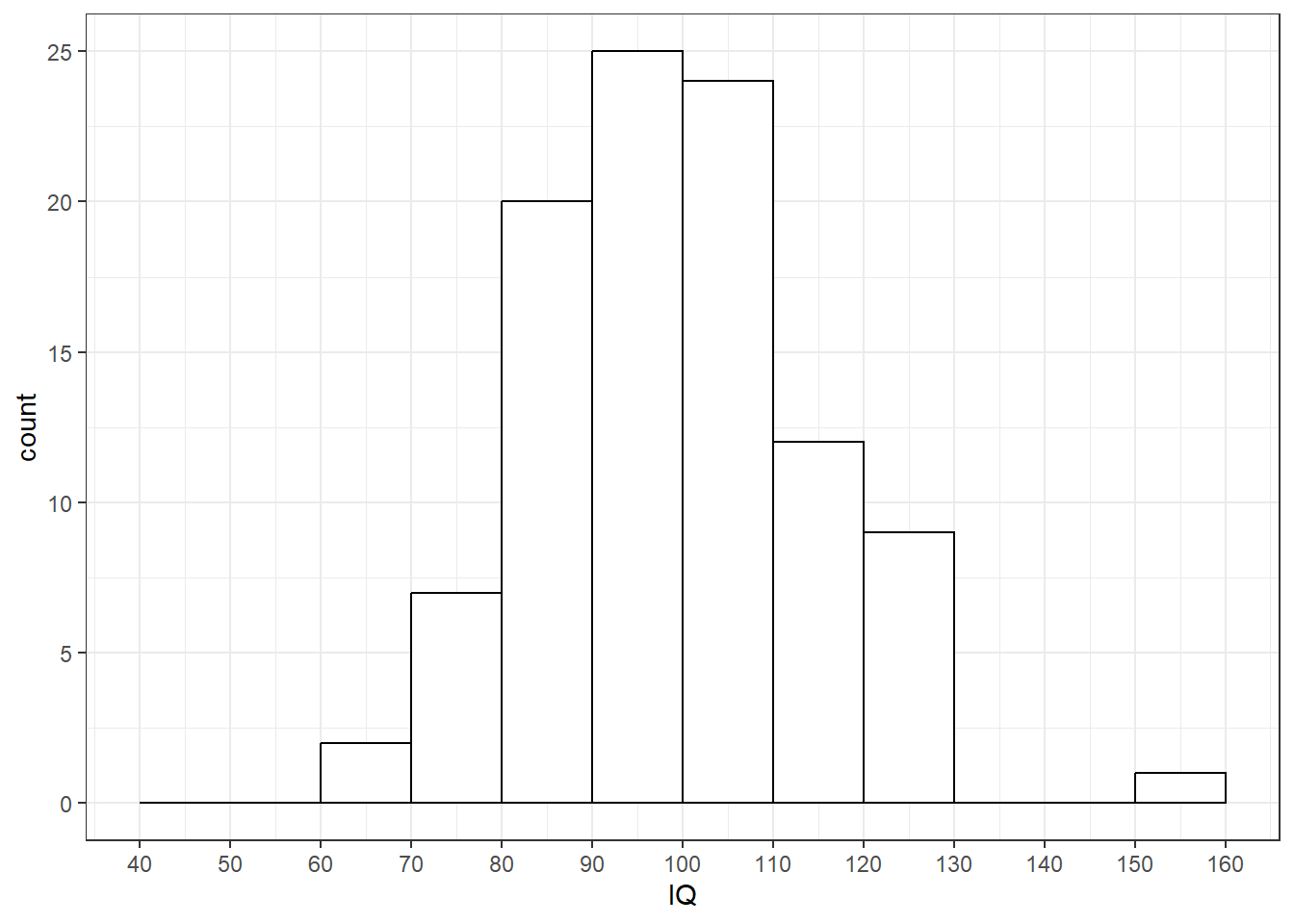
6.1 样本分布与总体分布的关系
若总体的均值mu与标准差sigma是未知的,我们可以用样本的均值与无偏标准差来估计总计的均值与标准差:
\[\begin{align} mu &= M_{sample} sigma &= s_{n-1} \end{align}\]
在上式中,\(M_{sample}\)是样本的均值,\({s_{n-1}}\)是样本的无偏标准差。
7 重复取样
使用一个样本计算得到的均值估计总体的均值产生的偏差可能较大,如果我们重复取样的过程,抽取多个样本,将多个样本的均值求均值,那么,我们将得到更为准确的估计值。下面,我们从人数N = 10000的总体中取出m = 1000个样本量n = 100的样本。
# 从总数为10000的样本中累计抽取1000个样本量为100的样本,存入samples
samples <- list()
for (index in 1:1000) samples[[index]] <- population10000[sample.int(10000, 100), ]
# 查看samples
length(samples)
## [1] 1000
head(samples[[1]])
## ID IQ
## 4095 4095 77
## 7241 7241 76
## 2867 2867 98
## 6947 6947 114
## 3949 3949 109
## 1464 1464 1338 1000个样本的均值的均值
与单个样本(例如:sample1)相比,1000个实际样本的均值的均值更加接近总体均值。
# 分别计算1000个样本的均值,一共得到1000个均值,存入samples_means
samples_means <- sapply(samples, function(x) mean(x$IQ))
head(samples_means)
## [1] 97.21 101.42 101.24 101.03 102.31 99.55
range(samples_means)
## [1] 95.11 106.23
head(samples_means)
## [1] 97.21 101.42 101.24 101.03 102.31 99.55
# 1000个实际样本的均值的均值。
mean(samples_means)
## [1] 100.0201
# 1000个实际样本的均值的标准差。
sum((samples_means-mean(samples_means))^2)/1000
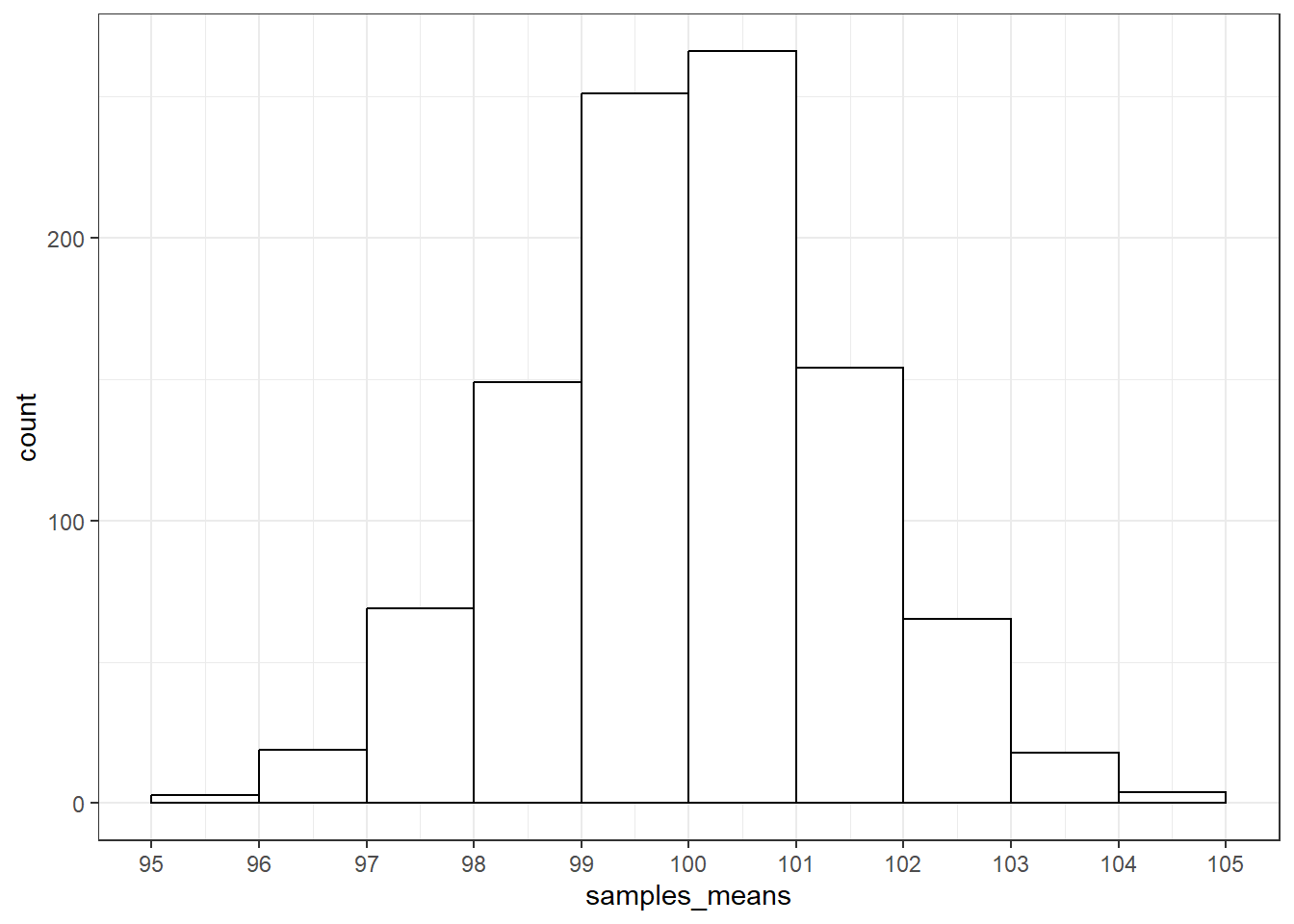
## [1] 2.2318559 抽样分布
抽样分布是1000个样本的均值的分布。这个分布中的每一个数据点是一个样本中100名被试的IQ的均值,而不是一个被试的IQ得分,这个分布的中心是是1000个样本的均值的均值,这个分布的标准差是1000个样本的均值的标准差。
9.1 抽样分布与总体分布、样本分布的关系
若总体的均值mu与标准差sigma是已知的:
\[\begin{align} M_{sampling} &= mu SD_{sampling} &= \frac{sigma}{\sqrt{n}} \end{align}\]
在上式中,n是样本量。
若总体的均值mu与标准差sigma是未知的,我们可以用样本的均值与无偏标准差来估计总计的均值与标准差:
\[\begin{align} M_{sampling} &= M_{sample} s_{sampling} &= \frac{s_{n-1}}{\sqrt{n}} \end{align}\]
在上式中,\(M_{sample}\)是样本的均值,\({s_{n-1}}\)是样本的无偏标准差。
本文到此结束。