代表性与显著性
Representativeness and significance
1 总体
我们捏造一个人数为10000人的总体,为10000名被试设定编号ID,并捏造出其IQ数据,设定IQ的均值为100,标准差为15。
# Population,总体
# 总体均值设置为100
mu <- 100
# 总体标准差设置为15
sigma <- 15
# 随机种子值设置为2026
set.seed(2026)
# 将ID与IQ存入数据表中
population10000 <- data.frame(
# 生成10000个ID(被试编号)
ID = seq(1:10000),
# 生成10000个均值为mu、标注差为delta的IQ分数
IQ = round(rnorm(10000, mean = mu, sd = sigma), 0)
)
# 查看数据表
# View(population10000)
# 查看数据表前6行
range(population10000$IQ)
## [1] 45 158
head(population10000)
## ID IQ
## 1 1 108
## 2 2 84
## 3 3 102
## 4 4 99
## 5 5 90
## 6 6 62
# 总体的实际均值
mean(population10000$IQ)
## [1] 100.0531
# 总体的实际标准差
sqrt(sum((population10000$IQ - mean(population10000$IQ))^2)/10000)
## [1] 15.017922 总体分布
总体分布(population distribution)是总体(10000名被试IQ得分)的分布。注意该分布的横纵坐标的全距。
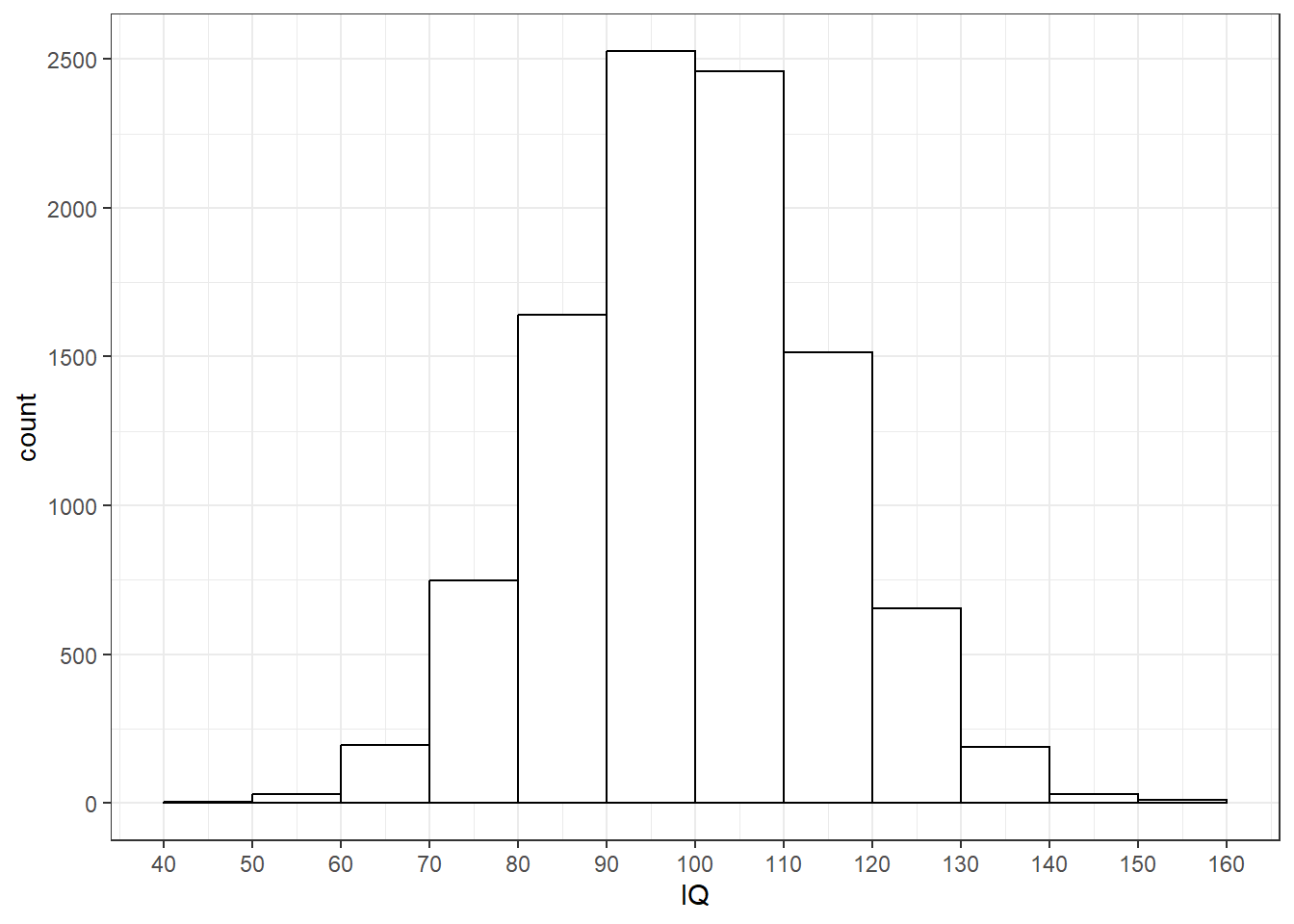
3 取样过程
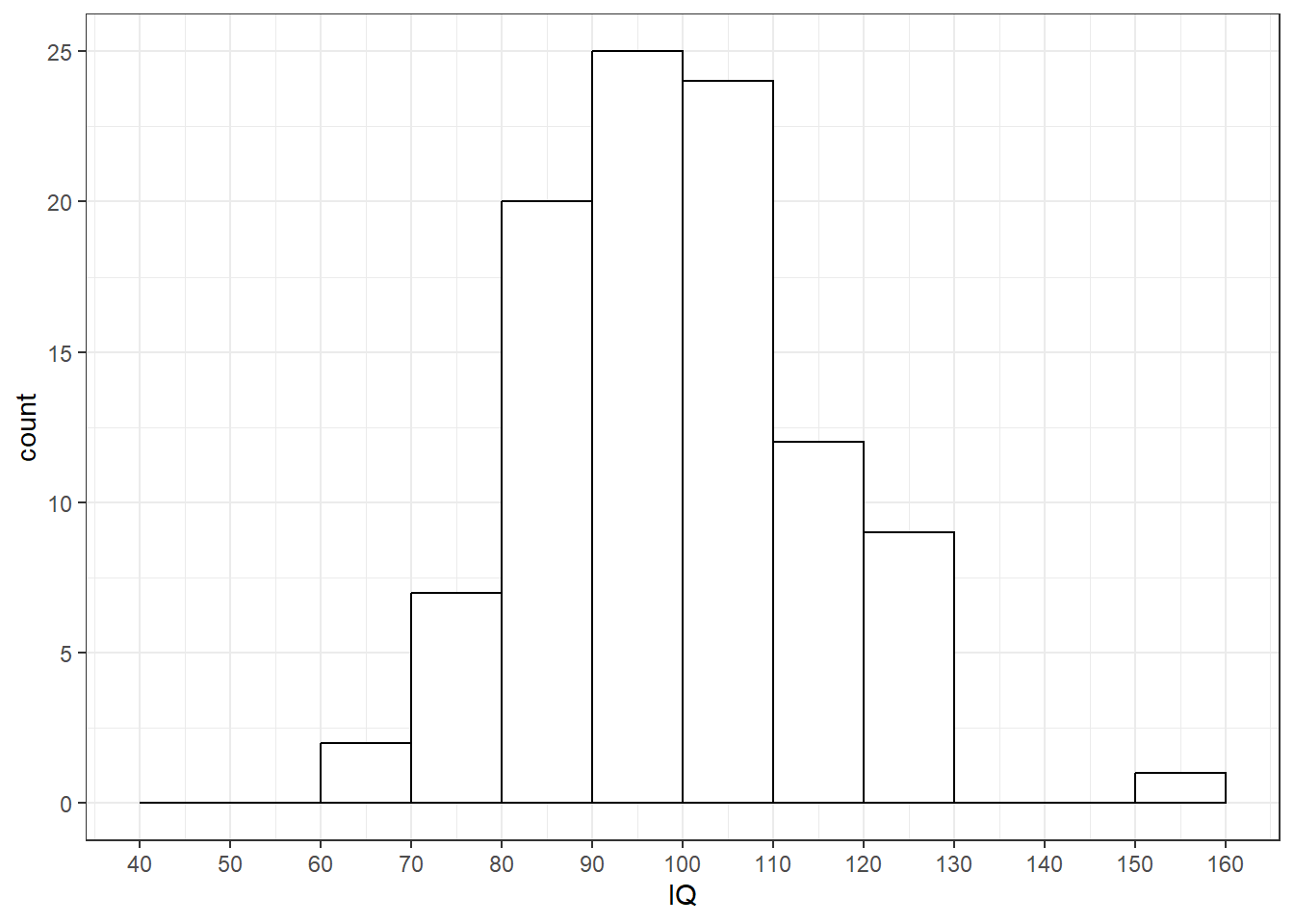
接下来,我们模拟取样的过程。我们从N = 10000的总体中随机抽取一个样本量n = 100的样本。我们称这个样本为sample1。
4 样本
查看sample1中的数据。注意:被试ID的顺序是乱的,这是由随机取样导致的。
5 基于样本估计总体均值与标准差
样本的均值是总体均值的无偏估计。样本的标准差总是小于总体的标准差,因此使用样本的无偏标准差作为总体标准差的无偏估计。尽管名为“无偏”,实际上还是有偏差的。
# 取值范围
range(sample1$IQ)
## [1] 65 154
# 计算sample1的IQ的均值
sample1_mean <- mean(sample1$IQ)
sample1_mean
## [1] 99.2
# 计算sample1的IQ的标准差
sample1_sd <- sqrt(sum((sample1$IQ - sample1_mean)^2)/100)
sample1_sd
## [1] 15.12614
# sample1的无偏标准差(基于sample1估计总体的标准差)
sample1_sd_unbiased <- sqrt(sum((sample1$IQ - sample1_mean)^2)/(100 - 1))
sample1_sd_unbiased
## [1] 15.20234
# 使用`sd()`函数计算sample1的无偏标准差(总体标准差的估计值)
sd(sample1$IQ)
## [1] 15.202346 样本分布
样本分布(sample distribution)是样本中100个被试IQ得分的分布。
6.1 样本分布与总体分布的关系
若总体的均值mu与标准差sigma是未知的,我们可以用样本的均值与无偏标准差来估计总计的均值与标准差:
\[\begin{align} mu &= M_{sample} sigma &= s_{n-1} \end{align}\]
在上式中,\(M_{sample}\)是样本的均值,\({s_{n-1}}\)是样本的无偏标准差。
7 重复取样
使用一个样本计算得到的均值估计总体的均值产生的偏差可能较大,如果我们重复取样的过程,抽取多个样本,将多个样本的均值求均值,那么,我们将得到更为准确的估计值。下面,我们从人数N = 10000的总体中取出m = 1000个样本量n = 100的样本。
# 从总数为10000的样本中累计抽取1000个样本量为100的样本,存入samples
samples <- list()
for (index in 1:1000) samples[[index]] <- population10000[sample.int(10000, 100), ]
# 查看samples
length(samples)
## [1] 1000
head(samples[[1]])
## ID IQ
## 4095 4095 77
## 7241 7241 76
## 2867 2867 98
## 6947 6947 114
## 3949 3949 109
## 1464 1464 1338 1000个样本的均值的均值
与单个样本(例如:sample1)相比,1000个实际样本的均值的均值更加接近总体均值。
# 分别计算1000个样本的均值,一共得到1000个均值,存入samples_means
samples_means <- sapply(samples, function(x) mean(x$IQ))
head(samples_means)
## [1] 97.21 101.42 101.24 101.03 102.31 99.55
range(samples_means)
## [1] 95.11 106.23
head(samples_means)
## [1] 97.21 101.42 101.24 101.03 102.31 99.55
# 1000个实际样本的均值的均值。
mean(samples_means)
## [1] 100.0201
# 1000个实际样本的均值的标准差。
sum((samples_means-mean(samples_means))^2)/1000
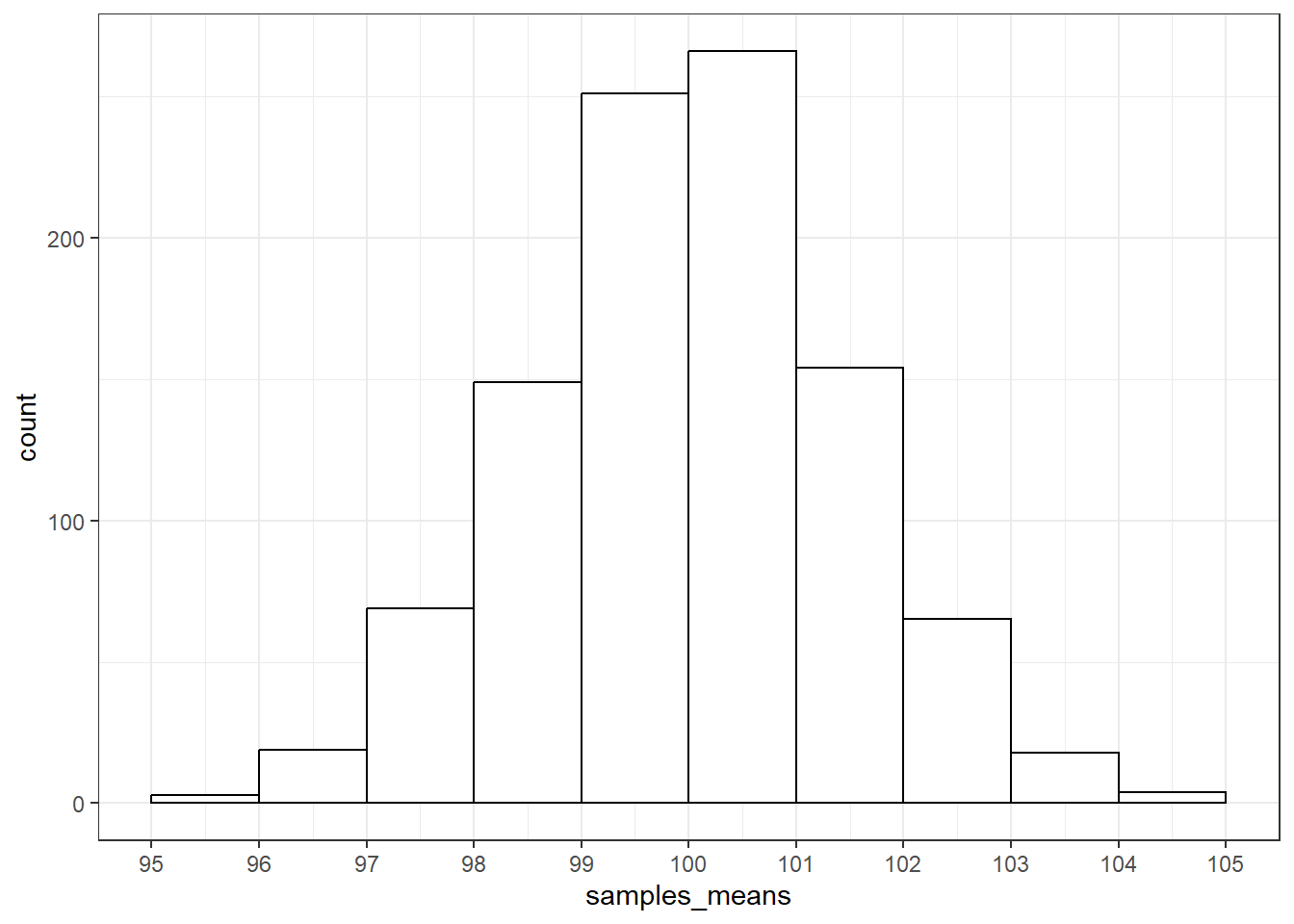
## [1] 2.2318559 抽样分布
抽样分布是1000个样本的均值的分布。这个分布中的每一个数据点是一个样本中100名被试的IQ的均值,而不是一个被试的IQ得分,这个分布的中心是是1000个样本的均值的均值,这个分布的标准差是1000个样本的均值的标准差。
9.1 抽样分布与总体分布、样本分布的关系
若总体的均值mu与标准差sigma是已知的:
\[\begin{align} M_{sampling} &= mu SD_{sampling} &= \frac{sigma}{\sqrt{n}} \end{align}\]
在上式中,n是样本量。
若总体的均值mu与标准差sigma是未知的,我们可以用样本的均值与无偏标准差来估计总计的均值与标准差:
\[\begin{align} M_{sampling} &= M_{sample} s_{sampling} &= \frac{s_{n-1}}{\sqrt{n}} \end{align}\]
在上式中,\(M_{sample}\)是样本的均值,\({s_{n-1}}\)是样本的无偏标准差。
10 代表性
集中趋势的统计指标能够代表一组数据(样本)的一般水平。换句话说,众数、中位数、均值对一组数据具有代表性(Representativeness)。
11 显著性
我们计算得到W研究中flourish1的均值为5.32,我们可以查到编号为1787的被试的幸福感得分为5.75。那么,该学生的幸福感是否高于幸福感的一般水平?尽管表面上该学生的幸福感得分高出样本均值0.43分,但这一差异可能是测量误差导致的。例如,在填写问卷时,学生经常在两个相近的选项(例如:6与7)上纠结,一分之差就会造成其幸福感得分的差异,但学生的幸福感水平实质上是相同的。概括地讲,统计上关注的“差异”并非“两个数值表面上看起来有差异”,因为数值上的差异可能是由测量误差与抽样随机性导致的,这种表面上的差异不能说明两个数值存在实质上的差异。如果两个数值具有实质上的差异,我们就称两个数值的差异显著(significant),或者说,两个数值的差异具有统计学意义。那么,判断该学生的幸福感水平与幸福感的一般水平差异显著的标准是什么呢?是概率。
12 差异显著的概率标准
我们在前面的章节学习了频数分布的一般规律:理想条件下,数据分布服从正态分布,左侧低分占少数,右侧高分占少数,中间中等分占绝大多数。换句话说,分数的高低是与其概率相联系的,极端低分和极端高分是小概率事件。统计上判断一个分数是否极端的标准为概率p < 0.05,p是probability的缩写。意即,分布在两侧尾部的极端得分(含左侧极低分与右侧极高分)占总数的5%。由于正态分布具有对称性,因此左侧尾部(左侧红线以左)占2.5%,右侧尾部(右侧红线以右)占2.5%。当得分落在两侧尾部5%的区域时,我们就说该得分与分布的中心(分布的均值)具有显著差异。
dat_plot <- data.frame(flourish1 = 1:10)
dat_ltail <- data.frame(
x = seq(1, 3.50, 0.01),
y = dnorm(seq(1, 3.50, 0.01),
mean = mean(well$flourish1),
sd = sd(well$flourish1)))
dat_rtail <- data.frame(
x = seq(7.14, 10, 0.01),
y = dnorm(seq(7.14, 10, 0.01),
mean = mean(well$flourish1),
sd = sd(well$flourish1)))
ggplot(dat_plot, aes(flourish1)) +
stat_function(fun = dnorm,
args = list(mean = mean(well$flourish1),
sd = sd(well$flourish1))) +
scale_x_continuous(breaks = 1:10) +
geom_area(data = dat_ltail,
mapping = aes(x, y),
fill = "grey") +
geom_area(data = dat_rtail,
mapping = aes(x, y),
fill = "grey") +
scale_y_continuous(expand = expansion(mult = c(0, 0.05))) +
geom_vline(xintercept = 5.32, linewidth = 1) +
geom_vline(xintercept = 5.75) +
annotate("text", x = 5.1, y = 0.1, label = "5.32") +
annotate("text", x = 6, y = 0.05, label = "5.75") +
theme_classic()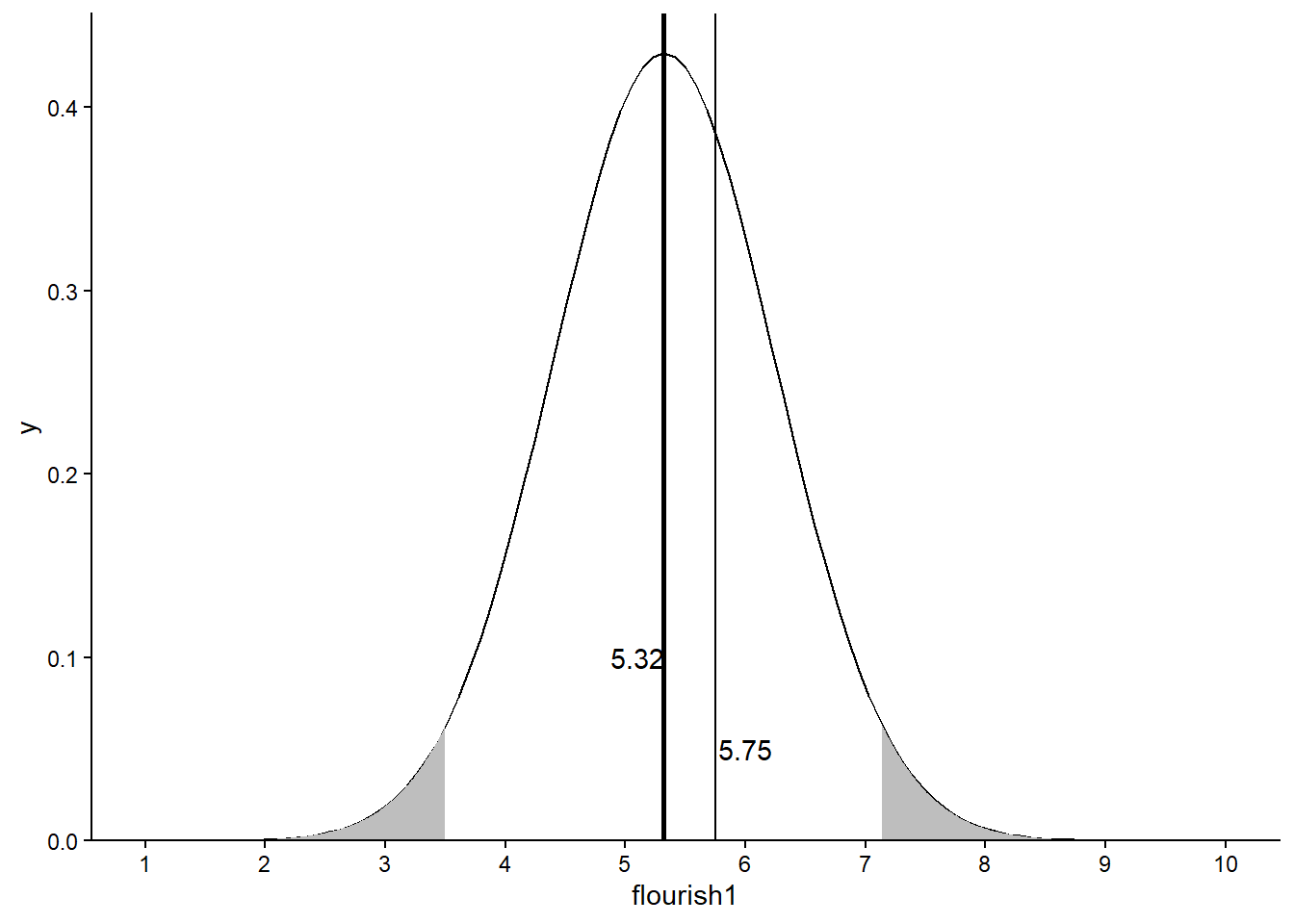
# 抽样分布。即,1000个样本的均值的分布。
ggplot(data.frame(samples_means), aes(samples_means)) +
geom_histogram(aes(y = after_stat(density)),
breaks = seq(95, 105, 0.2),
fill = "grey") +
scale_x_continuous(breaks = seq(95, 105, 1)) +
stat_function(fun = dnorm,
args = list(mean = mean(samples_means), sd = sd(samples_means)),
linewidth = 1,
color = "gold") +
geom_vline(xintercept = mean(samples_means) - qnorm(0.975)*sd(samples_means),
color = "red", linewidth = 1) +
geom_vline(xintercept = mean(samples_means) + qnorm(0.975)*sd(samples_means),
color = "red", linewidth = 1) +
geom_vline(xintercept = sample1_mean,
color = "chartreuse4", linewidth = 1) +
annotate("text", x = sample1_mean, y = 0.05,
label = "sample1 mean", color = "chartreuse4") +
theme_bw()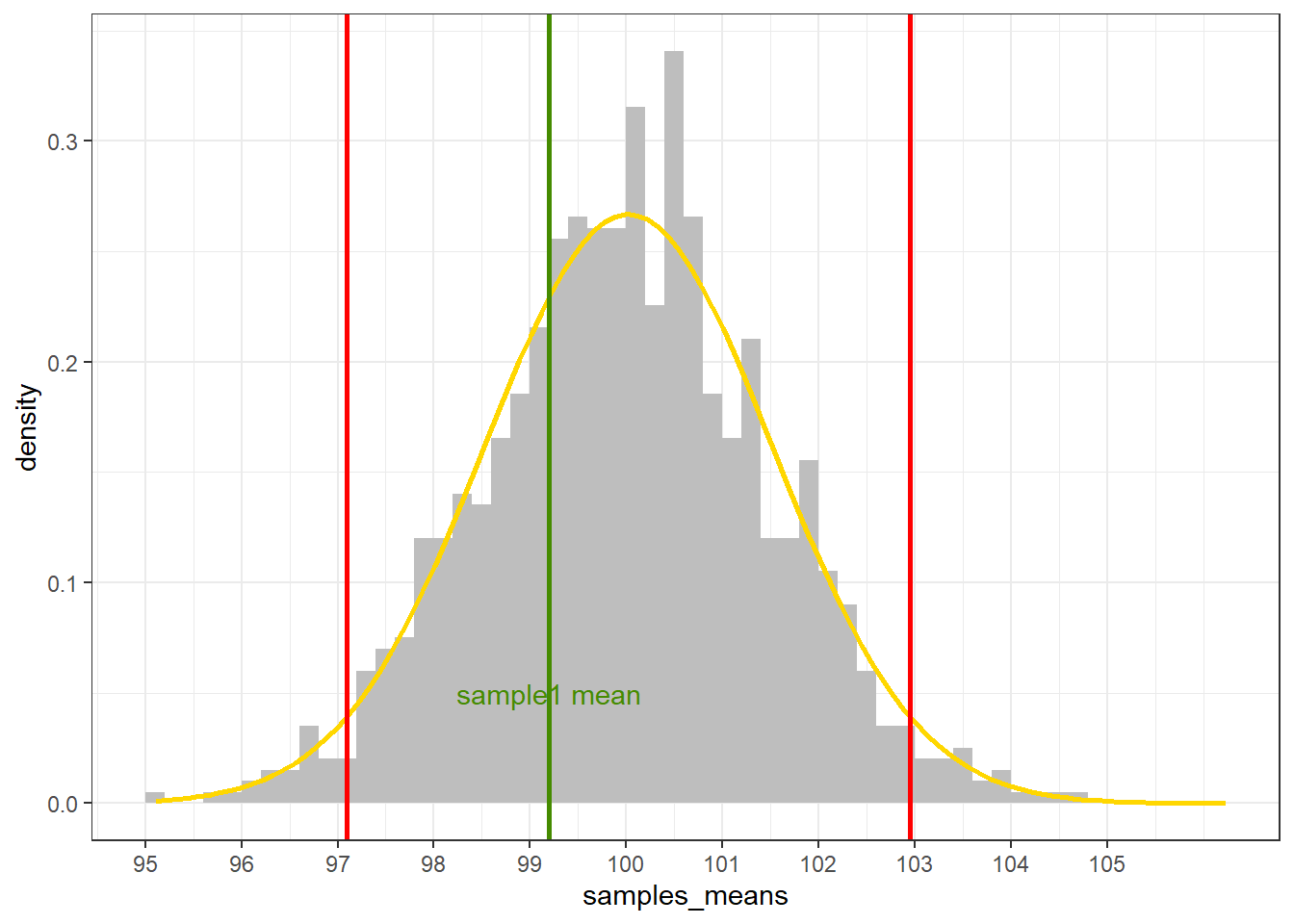
13 sample1均值与总体均值的直观比较
sample1均值为sample1_mean,比总体均值小。但是,这一差异是否显著?我们需要观察sample1的均值在抽样分布中的位置。上图蓝色线标出了sample1均值的位置。可见,sample1均值并未落在双侧尾部,故sample1均值与总体均值没有显著差异。
14 z分数与单样本z检验
理想情况下,抽样分布服从正态分布,正态分布的形状是固定的,横坐标与其概率具有严格的对应关系,只要我们知道了横坐标,我们就可以计算出这一横坐标所切割出来的尾部的精确概率。由于众多变量(例如:智商、年龄、身高)的单位不同,为了便于计算,我们可以将变量得分转化为z分数,将数据的分布转化为标准正态分布,从而计算z分数所对应的尾部的概率。z分数转换的公式如下,其中\(M_x\)为x的均值,\(SD_x\)为x的标准差:
\[ z = \frac{x-M_x}{SD_x} \]
转换为z分数后,z分数的均值为0,标准差为1。z分数的分布如下。
ggplot(data.frame(z = seq(-4, 4, 0.1)), aes(z)) +
scale_x_continuous(breaks = seq(-4, 4, 0.5)) +
stat_function(fun = dnorm,
linewidth = 1,
color = "gold") +
geom_vline(xintercept = qnorm(0.025),
color = "red", linewidth = 1) +
geom_vline(xintercept = qnorm(0.975),
color = "red", linewidth = 1) +
geom_vline(xintercept = (sample1_mean - mu)/(sigma/sqrt(100)),
color = "skyblue", linewidth = 1) +
annotate("text", x = -1, y = 0,
label = "z = -1.16",
color = "deepskyblue") +
theme_bw()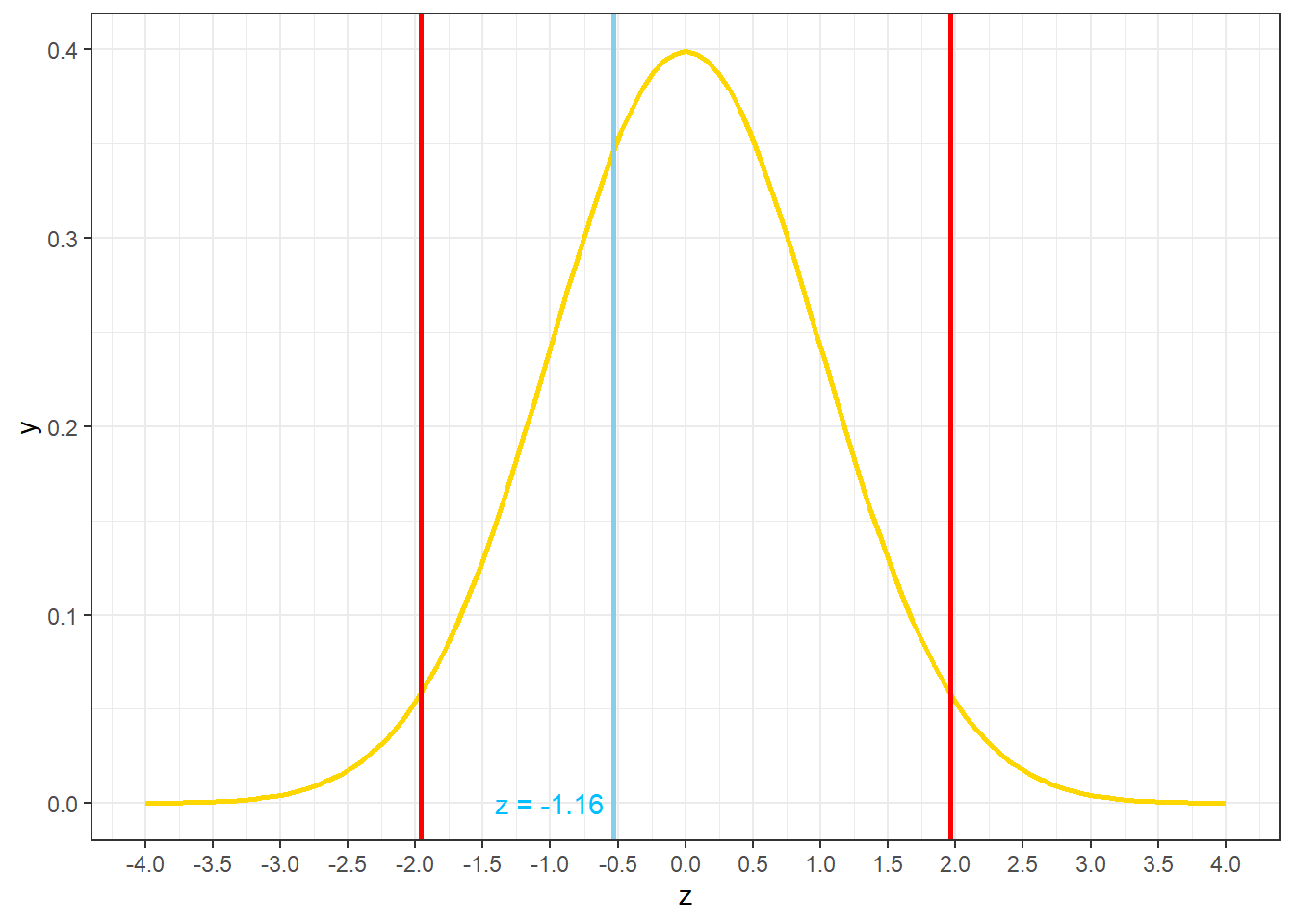
z分数的均值(分布的中心)为0,z的取值范围大致为[-4, 4]。z反映了一个得分在分布中的位置。当z < 0时,z位于分布中心的左侧,当z > 0时,z位于分布中心的右侧。已知z,pnorm()函数可以计算累积概率p(即上图中金色正态曲线与垂直线z包围的面积)。pnorm()默认计算从左到右的累积概率,即左侧尾部的概率。例如,当z = -1时,左尾的概率为0.1586553。另外,已知p,qnorm()函数可以计算z。
因此,我们可以将sample1均值转换为z分数,然后计算sample1均值在抽样分布中的尾部概率。理想情况下(例如:样本量n更大,抽取的样本的数量m更大),抽样分布的均值为\(\mu = 100\),抽样分布的标准差为\(\frac{\sigma}{\sqrt{n}} = \frac{15}{\sqrt{100}}=1.5\)。抽样分布的标准差通常被称为标准误(Standard Error),统计符号为SE。样本均值的标准误反映了样本均值估计总体均值的标准误差。
可得,z = -1.16,p = 0.25,sample1均值与总体均值100没有显著差异。
这里,我们计算z分数,继而计算p值的统计检验方法就是单样本z检验。单样本z检验的作用是在总体均值、标准差已知的情况下,比较样本均值与总体均值的差异。
15 t分数与单样本t检验
但是,总体均值与标准差通常是未知的,需要用样本的均值与无偏标准差进行估计。按照与单样本z检验相同的方法,我们可以计算出“z”及其p值。由于样本对总体的估计有偏差,由样本均值与样本无偏标准差估计得到的抽样分布与基于总体均值与总体标准差估计得到的抽样分布有偏差。因此,此时得到的“z”不是z,而是t。这一检验就是单样本t检验。
可见,单样本z检验计算得到的z值、p值与单样本t检验计算得到的z值、p值是接近的,统计结论是相同的。
事实上,我们不必手写上述略微复杂的代码来进行单样本t检验,t.test()函数可以帮我们做:
t.test.out <- t.test(sample1$IQ, alternative = "two.sided", mu = 100)
print(t.test.out)
##
## One Sample t-test
##
## data: sample1$IQ
## t = -0.52623, df = 99, p-value = 0.5999
## alternative hypothesis: true mean is not equal to 100
## 95 percent confidence interval:
## 96.18353 102.21647
## sample estimates:
## mean of x
## 99.2可见,t.test()检验的结果与我们编辑公式代码计算的结果是一样的。
16 自由度
在上面的t检验中,p值的计算会使用自由度(degree of freedom, df)这一统计量。什么是自由度?自由度是数据可以自由变化的程度。在前文中,我们对sample1均值进行单样本t检验,这一检验需要我们首先计算sample1的均值。当sample1的均值保持不变时,样本中只有n - 1 = 100 - 1 = 99个人的IQ值可以自由变化,因此自由度df = 99。我们以三个人的数据为例:假设张三、李四、王二的IQ的均值为100,我们在猜测张三、李四的IQ得分时可以任意猜测,张三、李四的IQ得分可以自由变化,假定张三、李四的IQ得分分别为140、90。那么接下来,王二的IQ得分不能任意猜测,王二的IQ得分不再自由,因为张三、李四、王二的IQ的均值为100,所以王二的IQ得分必须是:100*3 - 140 - 90 = 70。
17 t分布的自由度
在单样本t检验中,df = n - 1,其中n为样本量。样本的样本量可能不同,由样本均值与样本无偏标准差估计得到的抽样分布会随着样本量发生变化,样本量越大,由样本均值与样本无偏标准差估计得到的抽样分布会越接近基于总体均值与总体标准差估计得到的抽样分布。
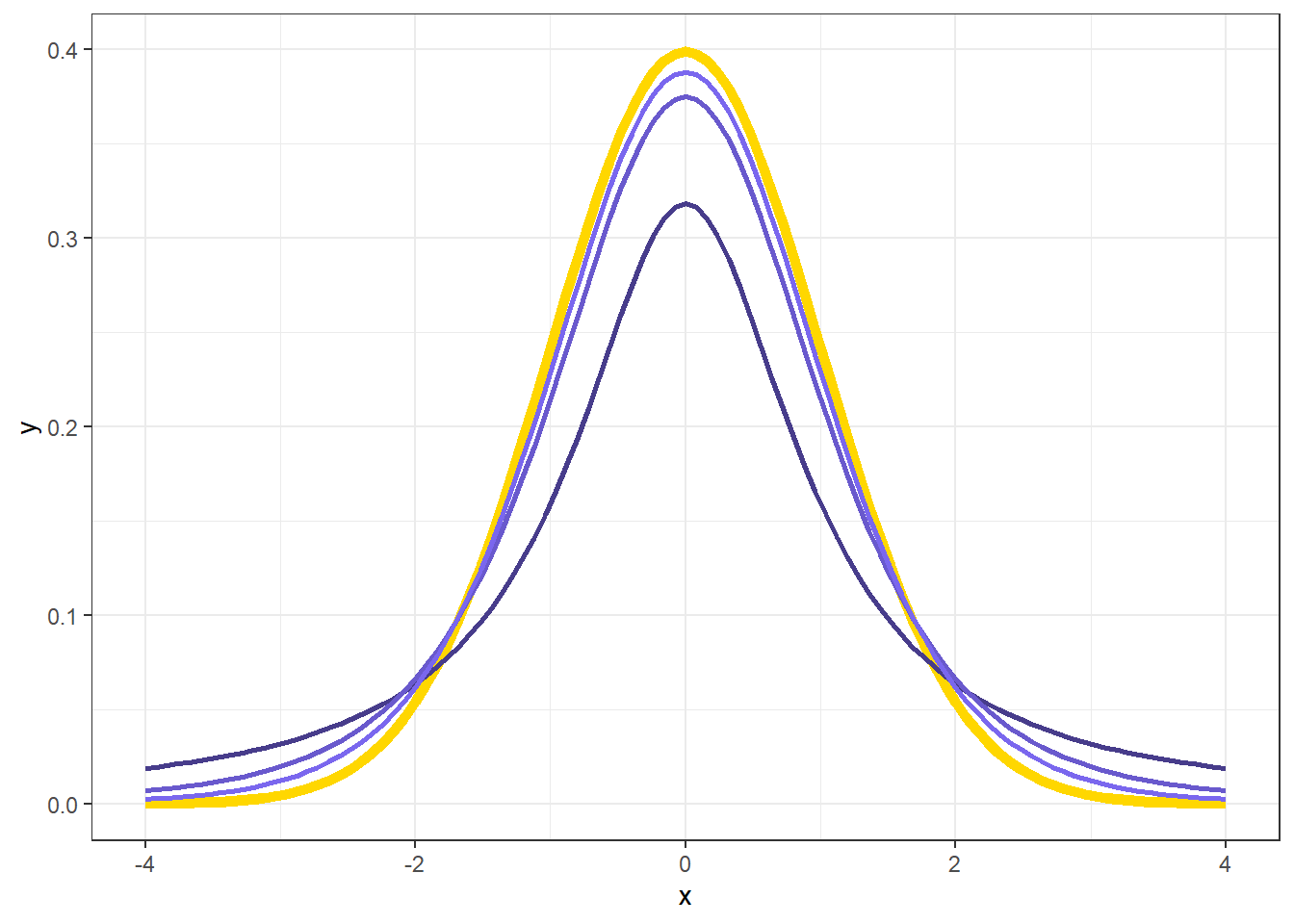
在下图中,金色曲线为z分布,蓝色线由深变浅为自由度为1、4、9时的t分布。可见,与z分布相比,样本量越小(df较小),t分布的尾部会越厚,这就造成了z检验与t检验的p值的差异。
ggplot(data.frame(x = seq(-4, 4, 0.1)), aes(x)) +
stat_function(fun = dnorm, color = "gold", linewidth = 2) +
stat_function(fun = dt, args = list(df = 1),
color = "slateblue4", linewidth = 1) +
stat_function(fun = dt, args = list(df = 4),
color = "slateblue3", linewidth = 1) +
stat_function(fun = dt, args = list(df = 9),
color = "slateblue2", linewidth = 1) +
theme_bw()