二分结果变量的回归
Regression on binary outcomes
1 概率与odds
一个事件 (例如,感冒) 有两种结果:发生或者不发生。我们用变量Y表示该事件,Y的取值有两个:1或0。Y是一个二分变量。发生的概率表示为P,那么不发生的概率则为1-P。下表呈现了一项对法国滑雪运动员的随机对照试验,该试验旨在考察维他命C与感冒的关系,安慰剂组不服用维他命C,维他命C组服用维他命C,经过一段时间后调查其是否患上感冒 (Muthen et al., 2016)。表中的第1-3列为频次。第4列为感冒的概率,其中0.221与0.122为条件概率,条件概率指的是在某种条件下的概率。0.221表示在安慰剂这种条件下的感冒的概率,0.122表示在维他命C这种条件下的感冒的概率。
| n | 未感冒 | 感冒 | 概率 | Odds | |
|---|---|---|---|---|---|
| 安慰剂组 | 140 | 109 | 31 | 0.221 | 0.284 |
| 维他命C组 | 139 | 122 | 17 | 0.122 | 0.139 |
| 总计 | 279 | 231 | 48 | 0.208 | 0.263 |
感冒的概率大,还是不感冒的概率大?统计学家常通过比值来比较概率的大小,这个比值被称为odds:
odds = P/(1-P)
Odds
odds ratio是概率的比值。
显然,当P = 1-P时,odds = 1;当P > 1-P时,odds > 1;当P < 1-P时,odds < 1。
可见,就总体而言(N = 279),感冒的odds为0.263,该值小于1,表明总体而言感冒的概率小于未感冒的概率。
2 Odds Ratio (OR)
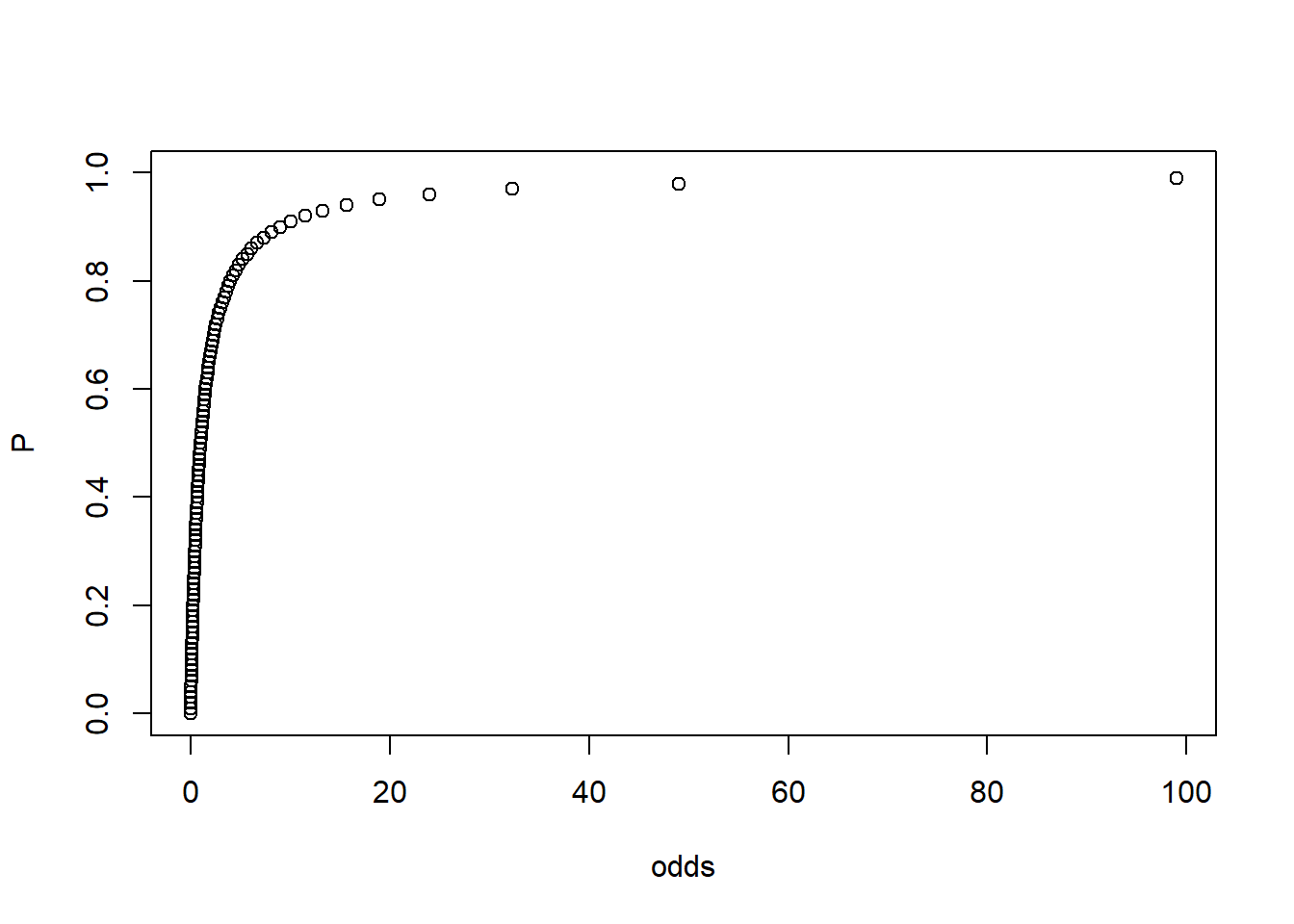
P与odds有怎样的关系?我们可以计算并作图观察:
可见,odds与P的关系具有单调性,odds越大,P越大,尽管它们之间的关系不是线性的。 因此,我们可以用odds比较不同条件下事件发生的概率。同样地,我们通过作比来比较odds的大小,这个比值被称为odds ratio(常被译为优势比)。
Odds Ratio (OR)
Oodds Ratio (OR) 是概率的比值的比值。
在前文的案例中,与未服用维他命C的人相比,服用维他命C的人是否不易感冒?安慰剂组(未服用维他命C)的odds为0.284,维他命C组的odds为0.139,那么,
odds ratio = odds维他命C/odds安慰剂 = 0.139/0.284 = 0.489
可得,与安慰剂组相比,维他命C组感冒的概率更小。
3 结果为二分变量的线性回归
当结果是二分变量时,我们如何用回归表示自变量与结果变量的的关系呢?让我们看一下下面这个例子。下面的数据描述了英国煤矿工人呼吸急促(breathlessness)这一症状与年龄的关系,第2列是各年龄的人数,第3列是有这一症状的人数,P是相应的比例。
| age | n | breathlessness | f | P | odds | logit |
|---|---|---|---|---|---|---|
| 22 | 1952 | 1 | 16 | 0.0081967 | 0.0082645 | -4.7957905 |
| 27 | 1791 | 1 | 32 | 0.0178671 | 0.0181922 | -4.0067648 |
| 32 | 2113 | 1 | 73 | 0.0345480 | 0.0357843 | -3.3302456 |
| 37 | 2783 | 1 | 169 | 0.0607258 | 0.0646519 | -2.7387382 |
| 42 | 2274 | 1 | 223 | 0.0980651 | 0.1087275 | -2.2189110 |
| 47 | 2393 | 1 | 357 | 0.1491851 | 0.1753438 | -1.7410066 |
| 52 | 2090 | 1 | 521 | 0.2492823 | 0.3320586 | -1.1024437 |
| 57 | 1750 | 1 | 558 | 0.3188571 | 0.4681208 | -0.7590289 |
| 62 | 1136 | 1 | 478 | 0.4207746 | 0.7264438 | -0.3195942 |
| 22 | 1952 | 0 | 1936 | 0.9918033 | 121.0000000 | 4.7957905 |
| 27 | 1791 | 0 | 1759 | 0.9821329 | 54.9687500 | 4.0067648 |
| 32 | 2113 | 0 | 2040 | 0.9654520 | 27.9452055 | 3.3302456 |
| 37 | 2783 | 0 | 2614 | 0.9392742 | 15.4674556 | 2.7387382 |
| 42 | 2274 | 0 | 2051 | 0.9019349 | 9.1973094 | 2.2189110 |
| 47 | 2393 | 0 | 2036 | 0.8508149 | 5.7030812 | 1.7410066 |
| 52 | 2090 | 0 | 1569 | 0.7507177 | 3.0115163 | 1.1024437 |
| 57 | 1750 | 0 | 1192 | 0.6811429 | 2.1362007 | 0.7590289 |
| 62 | 1136 | 0 | 658 | 0.5792254 | 1.3765690 | 0.3195942 |
首先,我们尝试以breathlessness为结果变量作线性回归,breathlessness是一个二分变量。这里需要补充一点背景知识:二分变量服从伯努利分布,二分变量Y的 (平均值) 期望为事件发生的概率P,二分变量Y的方差为P(1 - P)。当我们以breathlessness为结果变量作线性回归时,实际上是用年龄age预测breathlessness,该方程估计得到的是在相应年龄上的breathlessness的平均值,也就是breathlessness = 1 (有呼吸急促症状) 的概率。接下来我们看结果:
# 以breathlessness为结果变量的线性回归
lm.fit <- lm(breathlessness ~ age, weights = f, dat)
summary(lm.fit)
##
## Call:
## lm(formula = breathlessness ~ age, data = dat, weights = f)
##
## Weighted Residuals:
## Min 1Q Median 3Q Max
## -10.009 -6.059 3.269 12.543 17.326
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.268336 0.287116 -0.935 0.364
## age 0.009794 0.006735 1.454 0.165
##
## Residual standard error: 10.78 on 16 degrees of freedom
## Multiple R-squared: 0.1167, Adjusted R-squared: 0.06153
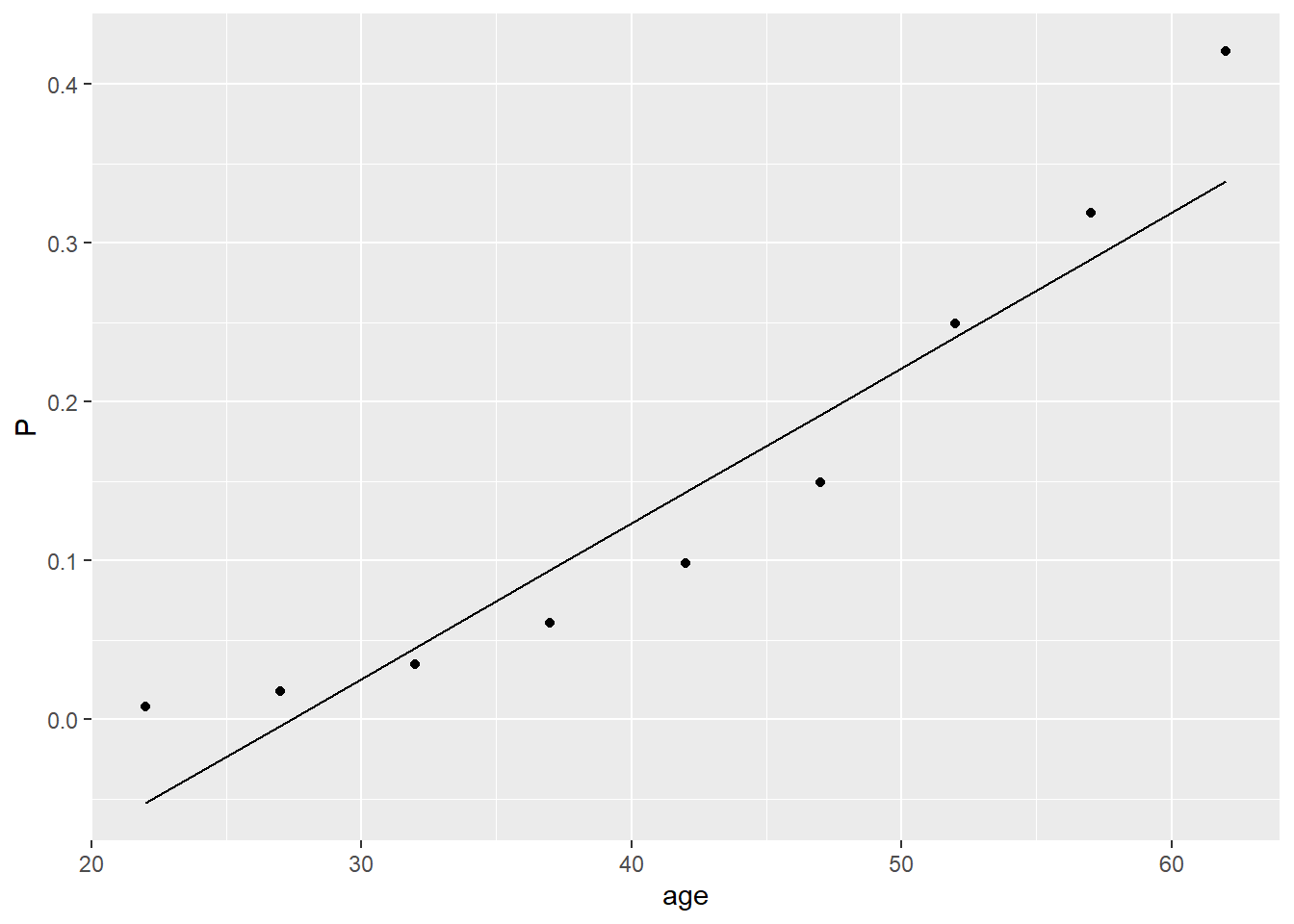
## F-statistic: 2.115 on 1 and 16 DF, p-value: 0.1652可见breathlessness = -0.268336 + 0.009794*age。我们可以根据该回归方程,使用age预测breathlessness,估计得到相应年龄breathlessness的患病率P_linear。在下图中,我们将实际的患病率P (散点图) 与回归方程估计得到的P_linear(直线) 进行对比,可以发现实际上breathlessness = 1的概率与age的关系不是一条直线,而是一条曲线,线性回归方程与实际数据的偏差较大。
4 Logit
当变量间关系不满足线性关系时,我们可以对原始数据进行一定的的转换,使其更加接近线性关系,继而再进行线性拟合。这里,我们可以对odds进行自然对数转换,将odds转化为以e为底的幂次:
odds = e^logit^
logit = log(odds)
对数转换后的变量为上表中的logit。log转换同样具有单调性,odds越大,logit越大。接下来,我们以logit为结果变量进行线性回归:
# 以breathlessness的logit为结果变量的线性回归
lm.fit2 <- lm(logit ~ age, subset = (breathlessness == 1), dat)
summary(lm.fit2)
##
## Call:
## lm(formula = logit ~ age, data = dat, subset = (breathlessness ==
## 1))
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.25431 -0.07937 0.04203 0.11581 0.14768
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -6.968911 0.178466 -39.05 1.88e-09 ***
## age 0.110338 0.004062 27.17 2.35e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1573 on 7 degrees of freedom
## Multiple R-squared: 0.9906, Adjusted R-squared: 0.9893
## F-statistic: 738 on 1 and 7 DF, p-value: 2.349e-08可见logit = -6.968911 + 0.110338*age。年龄的系数是正的,表明随着年龄的增长,logit会增加,即breathlessness的odds会增加,即breathlessness的患病概率会增加。
我们可以根据该回归方程,使用age预测breathlessness的logit,估计得到相应年龄的breathlessness的logit。在下图中,我们将实际数据的logit (散点图) 与回归方程 (直线) 进行对比,可以发现logit与age的关系近乎直线。
ggplot(dat[dat$breathlessness == 1, ], aes(age, logit)) +
geom_point() +
geom_abline(slope = 0.110338, intercept = -6.96891)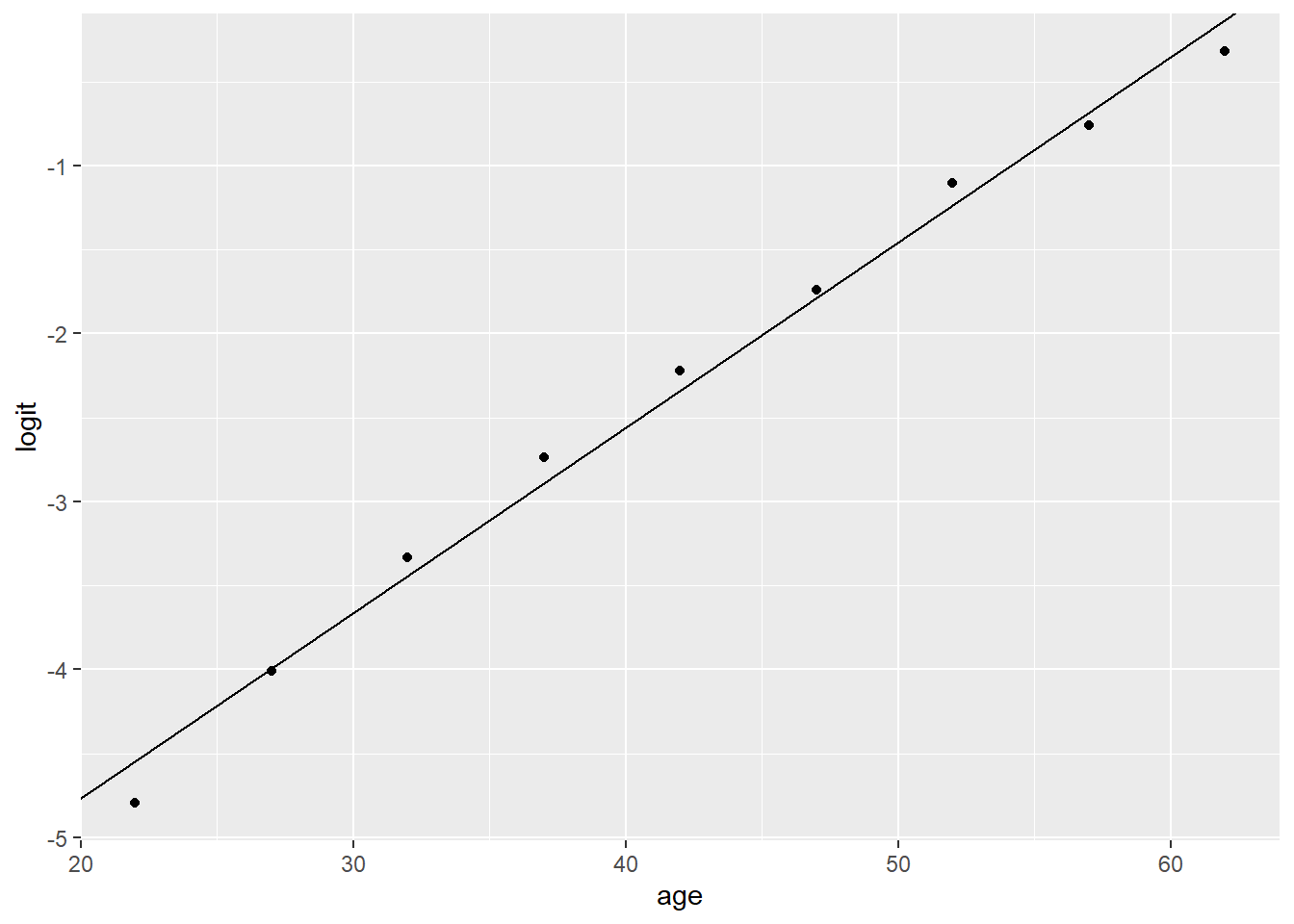
然而,线性回归假定结果变量的残差服从正态分布,这对于logit并不完美适用。既然我们将Y转换为了logit,更准确的统计方法是直接基于logit的分布 (即logistic累积概率分布) 来估计回归系数,这就是逻辑回归。
5 Logistic累积概率分布
逻辑回归用logistic累积概率分布函数拟合X与Y=1的概率的关系。一般的,logistic累积概率分布函数为:
\[P = \frac {1}{1 + e^{-(Y^*- \mu)/ \sigma}}\]
Y*是logistic回归方程的结果变量logit,一般的,我们有\(Y^* = b0 + b1\cdot X\),所以,logistic回归所基于的logistic分布函数是:
\[P = \frac {1}{1 + e^{-((b0 + b1\cdot X)- \mu)/ \sigma}}\]
在Logistic回归中,我们很少直接与\(\mu\)和\(s\)打交道,我们大都是在跟\(Y^*\)打交道。Logistic回归基于标准logistic分布,在标准logistic分布中,\(\mu = 0,s = 1\),因此,logistic分布函数简化为:
\[P = \frac {1}{1 + e^{-Y^*}} = \frac {1}{1 + e^{-(b0 + b1\cdot X)}}\]
b0与b1对logistic分布有怎样的影响?我们作图演示。注意,下图的横坐标是X,纵坐标是P。与P1相比,P2、P3的截距b0的变化会导致图中曲线沿横坐标轴水平平移。P3、P4的斜率b1的变化会导致曲线的陡峭程度变化,斜率越大越陡峭。
data_fake <-
tibble(X = seq(-6, 6, 0.1)) |>
mutate(
P1 = 1/(1 + exp(-1*X)),
P2 = 1/(1 + exp(-1*(X - 2))),
P3 = 1/(1 + exp(-1*(X - 4))),
P4 = 1/(1 + exp(-1*(0.5*X))),
P5 = 1/(1 + exp(-1*(2*X)))
) |>
pivot_longer(
cols = c(P1:P5),
names_to = "logit_formula",
values_to = "P"
)
ggplot(data_fake, aes(X, P, color = logit_formula, shape = logit_formula)) +
geom_point() +
scale_shape_manual(values = c(16, 15, 17, 16, 16))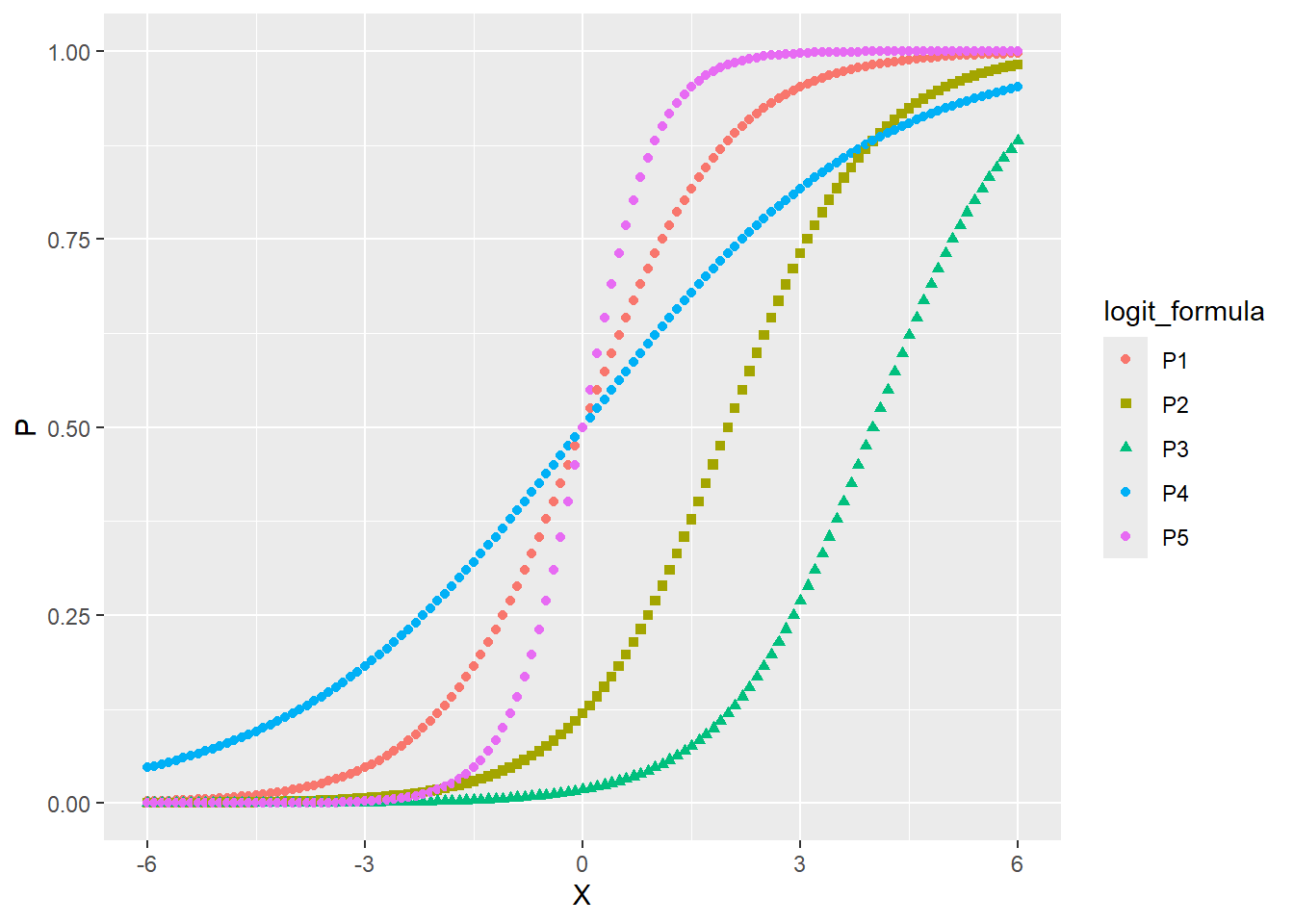
逻辑回归
逻辑回归就是以“逻辑值” (logit) 为“中间”结果变量的回归。
# 以breathlessness为结果变量的逻辑回归
glm.fit <- glm(
factor(breathlessness) ~ age,
family = binomial(link = "logit"),
data = dat,
weights = f
)
summary(glm.fit)
##
## Call:
## glm(formula = factor(breathlessness) ~ age, family = binomial(link = "logit"),
## data = dat, weights = f)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -6.564333 0.124152 -52.87 <2e-16 ***
## age 0.102492 0.002454 41.76 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 14318 on 17 degrees of freedom
## Residual deviance: 11993 on 16 degrees of freedom
## AIC: 11997
##
## Number of Fisher Scoring iterations: 6可见,logit = -6.564333 + 0.102492*age,该结果与前文得到的结果类似。
6 逻辑回归结果的解读
逻辑回归结果的解读分成三个层次:
- 回归系数的正负与显著性,
- odds, odds ratio,
- Y=1的概率。
我们从这三个层次上解读上述结果:
年龄的逻辑回归系数是正的,且达到了显著,表明年龄对于呼吸急促症状的发生概率具有显著的正向预测作用;
我们对回归方程等号两侧进行幂运算。一般的,对于逻辑回归方程Y^^ = b0 + b1 X,我们有:
\[odds = e^{Y^*} = e^{b0 + b1 \cdot X} = e^{b0} \cdot e^{b1 \cdot X}\]
在我们的案例中,我们可以得到:
\[odds = e^{logit} = e^{-6.564333 + 0.102492 \cdot age}\]
当X = 0时,\(odds_{X = 0} = e^{-6.564333}\)
当X = 1时,\(odds_{X = 1} = e^{-6.564333 + 0.102492} = e^{-6.564333} \cdot e^{0.102492}\)
\({Odds Ratio} = \frac {odds_{X = 1}} {odds_{X = 0}} = e^{0.102492} \approx 1.108\)
即,age每增加一个单位,患上呼吸急促症状的odds会提高为原来约1.108倍。
我们可以进一步计算概率的变化量。
一般的,对于逻辑回归方程\(Y^* = b0 + b1*X\),我们有:
\[\begin{align} P(Y = 1| b0 + b1 \cdot X) &= F(Y^*)\\ &= F(logit)\\ &= F(b0 + b1 \cdot X)\\ &= \frac {1}{1 + e^{-1 \cdot (b0 + b1 \cdot X)}} \end{align} \]
在上式中,函数F为标准logistic累积概率分布函数,该函数左边连着Y=1的概率,右边连着关于X的线性回归方程(b0 + b1*X),F的作用是对关于X的线性回归方程进行非线性转换,将其转换为Y=1的概率。这里的函数\[\frac {1}{1 + e^{-1*(logit)}}\]被称为连接函数(link function)。
连接函数
连接函数就是连接概率与线性回归方程的非线性函数。
那么,我们可以基于连接函数,使用年龄估计相应年龄患上呼吸急促症状的概率P_logistic。结果如下图所示。可见,患上呼吸急促症状的概率随年龄而增加。注意,P(Y = 1| b0 + b1*X)与X的关系不是线性关系,对于不同水平的X,X增加一个单位所导致的P_logistic的变化量是不同的。
dat$P_logistic <-
1 / (1 + exp(-1 * (-6.564333 + 0.102492 * dat$age)))
ggplot(dat[dat$breathlessness == 1, ], aes(age, P_logistic)) +
geom_point() +
geom_path()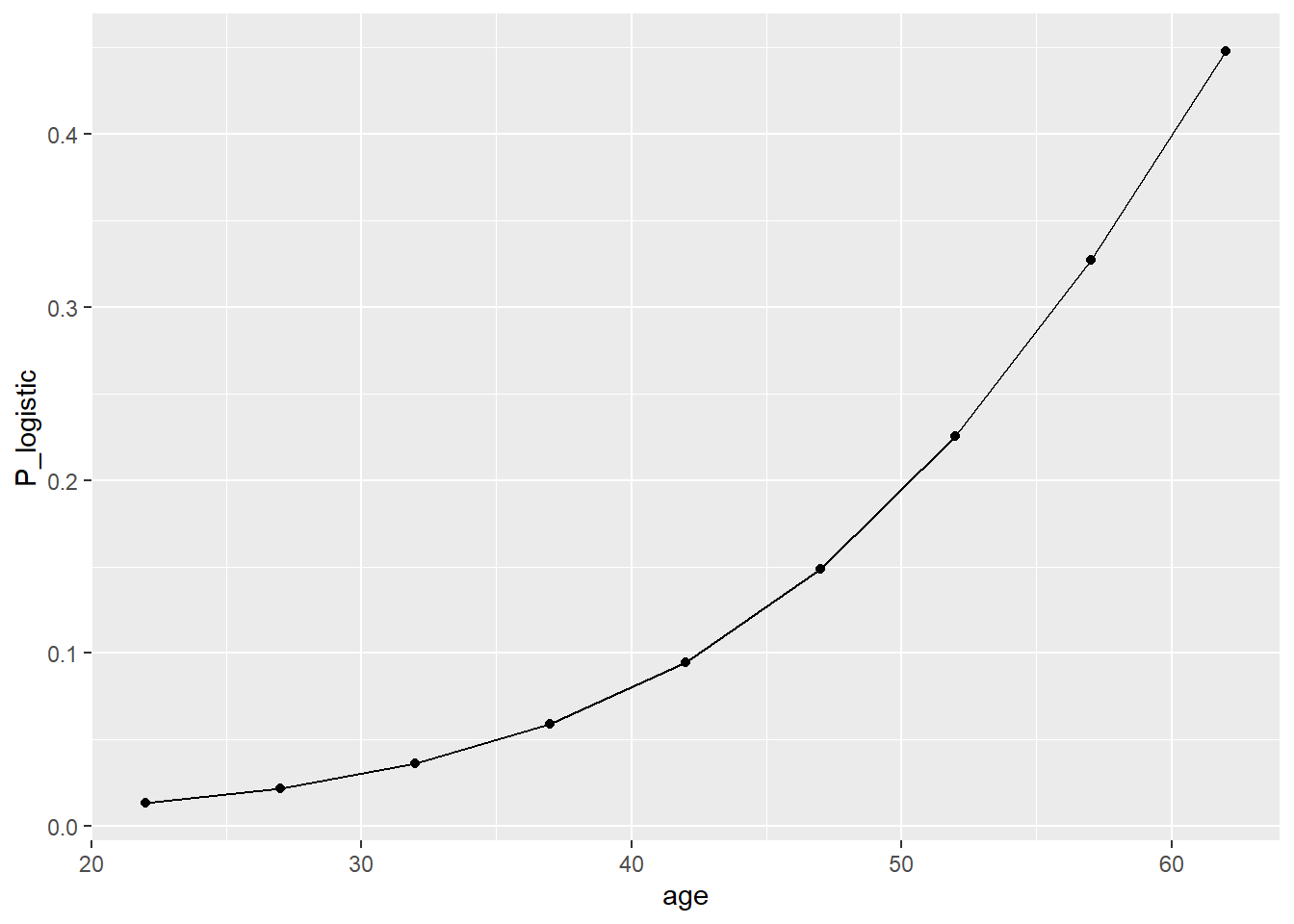
dat[1:9, c("age","logit", "P_logistic")]
## age logit P_logistic
## 1 22 -4.7957905 0.01326191
## 2 27 -4.0067648 0.02194452
## 3 32 -3.3302456 0.03610368
## 4 37 -2.7387382 0.05884899
## 5 42 -2.2189110 0.09451869
## 6 47 -1.7410066 0.14839957
## 7 52 -1.1024437 0.22535132
## 8 57 -0.7590289 0.32688913
## 9 62 -0.3195942 0.44773437我们比较32岁与37岁患上呼吸急促症状的概率。前面计算得到,32岁时患上呼吸急促症状的概率估计为0.036,小于37岁时的概率0.059。
7 Probit回归
前文图4可以看出logistic累积概率分布图与正态累积概率分布图近似。我们可以将其作图比较。在下图中,横坐标为Y*,纵坐标为累积概率P,红色表示标准logistic分布,绿色表示正态分布。可见,正态累积概率分布与logistic累积概率分布是接近的。
Y_star <- seq(-6, 6, 0.1)
P_logistic <- 1/(1 + exp(-Y_star))
P_norm <- pnorm(Y_star)
dat_logistic_norm <-
tibble(Y_star,P_logistic,P_norm) |>
pivot_longer(cols = c(P_logistic, P_norm),
names_to = "dist",
values_to = "P")
ggplot(dat_logistic_norm, aes(Y_star, P, color = dist)) +
geom_point()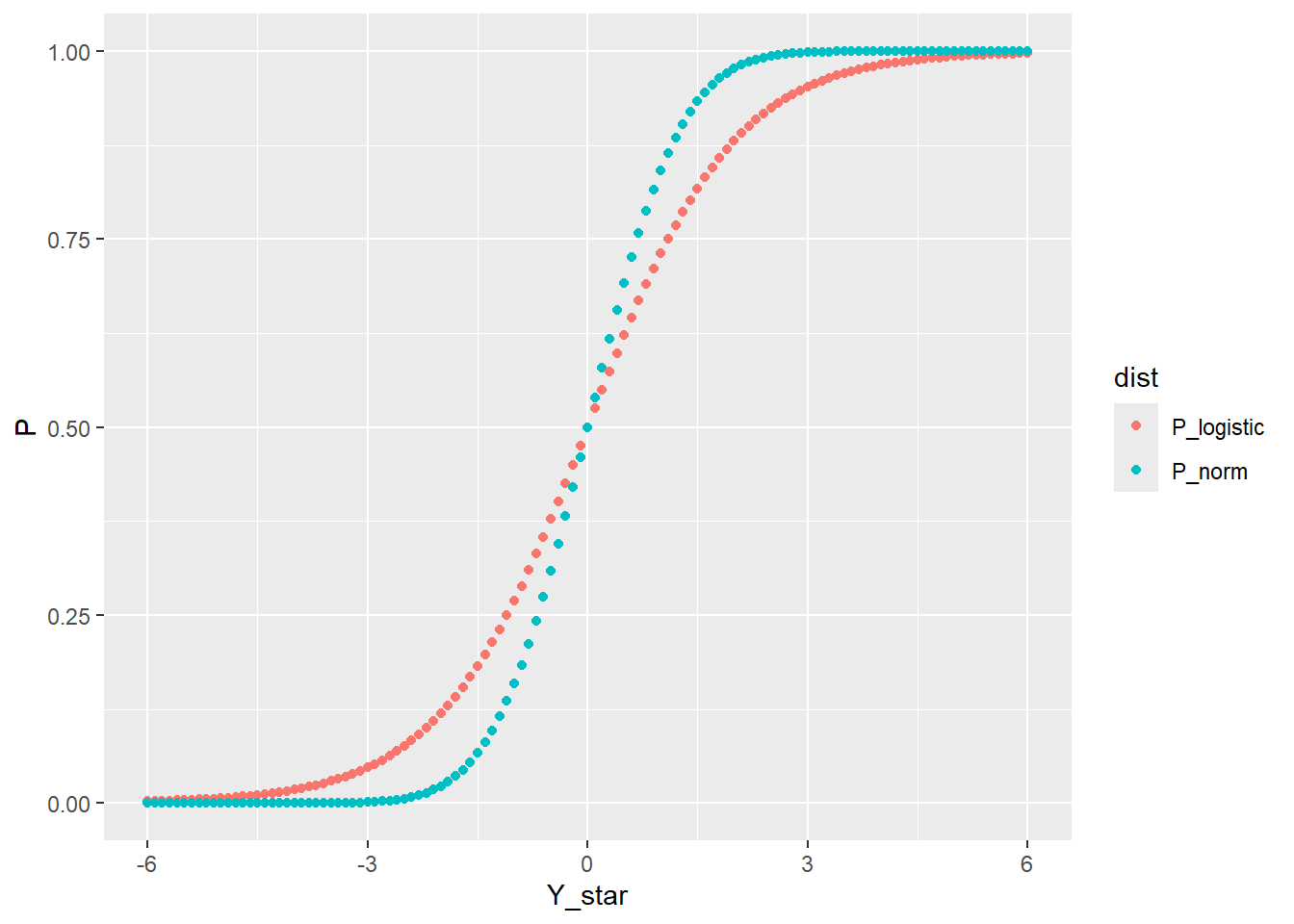
所有分布的累积概率都是从0变成1,是否可以用正态累积概率函数作为连接函数 (link function ) 来拟合二分变量Y从0变成1的概率变化呢?可以,这就是probit回归。一般的,对于probit回归方程,我们有:
\[ \begin{align} P(Y=1|b0+b1 \cdot X) &= \Phi(Y^*)\\ &= \Phi(probit)\\ &= \Phi(b0+b1 \cdot X)\\ &= \int_{-\infty}^{b0+b1 \cdot X} \phi(z; 0, 1) dz \end{align} \]
在上式中,\(\Phi(b0+b1 \cdot X)\)是连接函数,该函数是标准正态累积概率分布函数(z的均值为0、方差为1),该函数计算正态分布中从负无穷到\(z = probit = b0+b1 \cdot X\)的累积概率。注意:逻辑回归方程的结果变量实际上是logit,不是Y,logit是logistic累积概率分布的横坐标;而probit回归方程的结果变量实际上是probit,也不是Y,其中probit是标准正态累积概率分布的横坐标,通过对\(P(Y=1|b0+b1 \cdot X)\)作\(\Phi\)的逆运算,即\(\Phi^{-1}(P)\),我们可以计算得到\(probit\):
\[Probit(P) = \Phi^{-1}(P)\]
Probit回归
Probit回归就是以probit为“中间”结果变量的回归。
我们对前文的案例作probit回归:
# 以breathlessness为结果变量的probit回归
glm.fit <- glm(
factor(breathlessness) ~ age,
weights = f,
family = binomial(link = "probit"),
dat
)
summary(glm.fit)
##
## Call:
## glm(formula = factor(breathlessness) ~ age, family = binomial(link = "probit"),
## data = dat, weights = f)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.584158 0.061762 -58.03 <2e-16 ***
## age 0.054844 0.001272 43.13 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 14318 on 17 degrees of freedom
## Residual deviance: 11981 on 16 degrees of freedom
## AIC: 11985
##
## Number of Fisher Scoring iterations: 5可得,Probit = -3.584158 + 0.054844*age。
8 Probit回归结果的解读
我们可以根据该方程计算probit值,将probit值作为标准正态分布的横坐标,然后计算相应的累积概率P_probit。
dat$probit <- -3.584158 + 0.054844*dat$age
dat$P_probit <- pnorm(dat$probit)
dat[1:9, c("age","probit", "P_probit")]
## age probit P_probit
## 1 22 -2.37759 0.008713095
## 2 27 -2.10337 0.017716719
## 3 32 -1.82915 0.033688570
## 4 37 -1.55493 0.059981371
## 5 42 -1.28071 0.100147773
## 6 47 -1.00649 0.157089960
## 7 52 -0.73227 0.232001893
## 8 57 -0.45805 0.323458260
## 9 62 -0.18383 0.4270734109 回归系数的估计方法
线性回归的拟合目标是使预测Y的误差平方和最小。Probit回归与Logistic回归一样,其拟合目标都是使预测Y的准确率 (似然函数) 最大,即,使似然函数的值最大:
\[L = \prod_{i}^n P_i^{Y_i} \cdot (1 - P_i)^{1 - Y_i}\]
使下面的函数的值最大 (下面的函数是似然函数的对数函数) :
\[logL = \sum_i^n Y_i logP_i + (1-Y_i)log(1-P_i)\]
其中,\(P_i=Prob(Y_i = 1|X_i)\),\(i\)表示个案的编号。
回归系数为多少时上述函数的值最大?幸运地是,回归系数不需要我们手动去计算,寻找最优解的这一过程将由计算机完成。
10 阈限 \(\tau\)
有时,logit与probit也表示为\(Y^*\),\(Y^*\)被称为Y的潜在变量 (underlying variable) 。尽管Y是二分变量,取值只能是0或者1,但每个case为0或者1的潜在倾向是不同的,潜在变量\(Y^*\)就反映了这种倾向,\(Y^*\)越大,Y的取值越可能是1。我们为\(Y^*\)设定一个阈限\(\tau\),当\(Y^* > \tau\)时,我们就预测Y=1,当\(Y^* \leq \tau\)时,我们就预测Y=0。一般情况下,\(\tau\)为P=0.5时的\(Y^*\)的值,此时\(\tau = Y^* = 0\) 。可以看出,实际上\(\tau\)这个参数具有意义、易于理解。
lavaan与Mplus一样,当结果变量是分类变量时默认使用probit回归。与传统的逻辑回归或者probit回归不同,lavaan与Mplus的计算结果中没有报告截距,而是报告了阈限thresholds:
model <- "
breathlessness ~ age
"
fit <- sem(model,
dat,
ordered = "breathlessness",
sampling.weights = "f")
summary(fit)
## lavaan 0.6-19 ended normally after 2 iterations
##
## Estimator DWLS
## Optimization method NLMINB
## Number of model parameters 2
##
## Number of observations 18
## Sampling weights variable f
##
## Model Test User Model:
## Standard Scaled
## Test Statistic 0.000 0.000
## Degrees of freedom 0 0
##
## Parameter Estimates:
##
## Parameterization Delta
## Standard errors Robust.sem
## Information Expected
## Information saturated (h1) model Unstructured
##
## Regressions:
## Estimate Std.Err z-value P(>|z|)
## breathlessness ~
## age 0.055 0.025 2.192 0.028
##
## Thresholds:
## Estimate Std.Err z-value P(>|z|)
## brethlssnss|t1 3.584 1.096 3.270 0.001
##
## Variances:
## Estimate Std.Err z-value P(>|z|)
## .breathlessness 1.000截距在哪里?前文第5部分介绍了logistic分布函数,这个函数实际上同时包含截距b0与\(\mu\),\(\mu\)就是阈限。当我们使用glm()函数进行logistic回归与probit回归时,glm()设定参数\(\mu=0\),b0自由估计,一般b0的估计值不等于0。而在lavaan与Mplus的参数设置中,截距b0为0,阈限\(\mu\)自由估计,这种情况下\(\mu\)的估计值一般不等于0。不论是令b0=0、估计\(\mu\),还是令\(\mu=0\)、估计b0,logistic分布函数中\((b0 + \mu)\)为常数,且保持不变,因此令b0=0、估计\(\mu\)时,\(\mu=-b0\)。在上面的结果中,brethlssnss|t1为3.584,因此,breathlessness原本的截距为-3.584。probit回归对截距与阈限的参数设定与此类似。
lavaan与Mplus设定参数的方法可以理解为“参数重设”的过程:
第一步,基于标准logistic累积概率分布或标准正态累积概率分布,设定\(\tau = 0\),估计得到逻辑回归方程或probit回归的截距为b0,一般b0的估计值不等于0;
第二步,设定\(b0_{new} = 0\),重新估计回归方程,此时估计得到\(\tau_{new} = -b0\)!这就是lavaan与Mplus最终报告的结果。
观察图5,我们可以将上述“参数重设”过程想象为“坐标系不动、将累积概率分布图向左平移b0个单位”,或者“累积概率分布图不动、将纵坐标向右平移b0个单位”,使得分布中心由\(\tau = 0\)移动到新的位置\(\tau = -b0\)。平移之后,lavaan与Mplus所基于的logistic累积概率分布与正态累积概率分布的中心不再是0,因此lavaan与Mplus所基于的logistic累积概率分布与正态累积概率分布不再是标准分布。
11 拟合程度的比较
下面,我们基于前文的线性回归 (直接以Y为结果变量作线性回归) 、logistic回归与probit回归分别估计Y=1的概率,得到P_linear(红色),P_logistic (黄色) ,P_probit (绿色) ,并将其与实际的P (蓝色点) 进行比较。可见,线性回归的拟合较差,logistic回归与probit回归对实际数据的拟合较好。
前文提到,logistic回归与probit回归的参数估计旨在使预测的正确率最大,即,使似然函数值最大。在logistic回归与probit回归的计算结果中通常会报告Deviance、AIC、BIC,这三个指标都是基于似然函数值计算出来的。Deviance、AIC、BIC越小,其拟合越好。通过对前文报告的Deviance与AIC进行比较,我们可以看出probit对数据的拟合更好。一般情况下,probit回归对数据的拟合程度优于logistic回归。
# label: fig-6
ggplot(dat[dat$breathlessness == 1, ], aes(x = age)) +
geom_path(aes(y = P_linear), color = "red", linewidth = 1) +
geom_path(aes(y = P_logistic),
color = "yellow",
linewidth = 1) +
geom_path(aes(y = P_probit),
color = "green",
linewidth = 1) +
geom_point(aes(y = P), color = "blue", size = 3)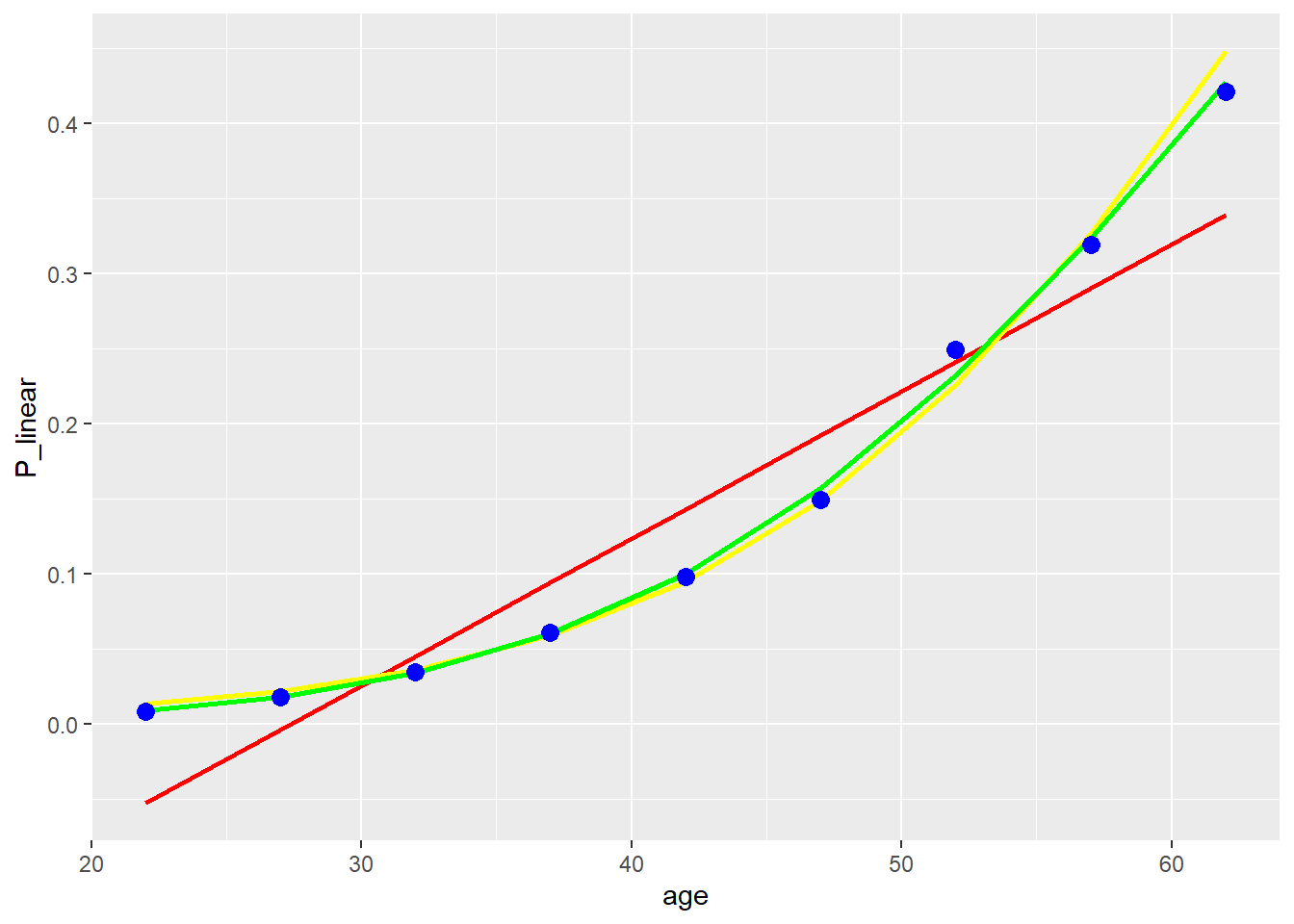
12 参考文献
Muthen, B.O, Muthen, L.K., & Asparouhov, T. (2016). Regression and Mediation Analysis using Mplus. Los Angeles, CA: Muthen & Muthen.